Tech
I'm using AutoMySQLBackup v2.5 and haven't upgraded to v3.0 because the new version splits out config from code (nice) but also expects you to put everything in /etc (not nice). It's a fairly simple script made complicated by this new version which even includes an installer script now, which is more reason to keep with the old version.
Some changes I made:
OPT=" --quote-names --opt --skip-lock-tables"
I'm running this script out of cron and I don't want to lock tables which the web server is serving, even if it means some rows will be out of sync.
Then I change all "rm -fv" to "rm -f" because OpenBSD rm doesn't have a "-v" option, which if my assumption is correct means "verbose" and it's not useful in this script.
Since my databases aren't so small anymore, I've had to set MAXATTSIZE="20000". I also want to filter certain tables (big ones that never change, cache and log tables) and AutoMySQLBackup 3.0 has a new setting CONFIG_table_exclude for this.
The section of new code that does this is:
if ((${#CONFIG_table_exclude[@]})); then for i in "${CONFIG_table_exclude[@]}"; do opt=( "${opt[@]}" "--ignore-table=$i" ) done fi
In 2.5 we can add these tables manually to the OPT variable after the "
OPT" line, e.g.
$OPT="$OPT --ignore-table=foo.bar --ignore-table=foo.baz"
This saves a lot of disk space and space in my Gmail account used for storing backups.
- tomo's blog
- Login to post comments
- Comments
My latest Chrome extension is a quick wrapper around a "service" (hoping the provider see it that way :) to compress English text and get around the 140 character bound on Twitter.
Twitter Decoder Ring: https://chrome.google.com/webstore/detail/idcnolgflhcckjdfpfbcehjocggffdjk
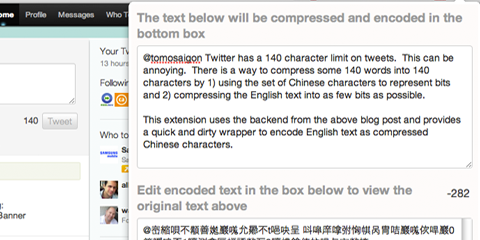
Twitter has a 140 character limit on tweets. This can be annoying when you are writing something and end up just slightly over (seeing negative character counts). So a lot of third party solutions have sprung up to allow one to tweet longer tweets by basically linking to a blog post. For example, TweetDeck does this. There is a way to compress some 140 words into 140 characters by 1) using the set of Chinese characters to represent bits and 2) compressing the English text into as few bits as possible.
For example, the entire paragraph above compresses into this non-sensical Chinese character string: 顜善嬔巖嗴允曏不t唈吷呈 呌噑庠嗱鲷凸亥丂仨丶乇儓乓(劗揦允圫s囸 严懦倡侭鹔丘柺槐嫢忒爠t唈堺倱t唈婐丕珹埼円七哢蠧呕囫 自t唈吷讴鏞弣恟帺呙冑咭巖嗴佽哻巖0簝噯呝丕1哼测樖匡螎諑歘丂2哼檂鎗俫抆哻与亩歘挍叜
I have always thought it a bit unfair that Chinese Twitter users get to say a lot more in 140 characters than we English-speakers do, because each Chinese character essentially represents an idea and often a complete word, rather than just a sound in an alphabet (like the Latin, Arabic, Hebrew, or even Vietnamese alphabets). On the other hand, Chinese Twitter users aren't allowed to access Twitter so I guess it's a draw.
A description of the project to compress English words into Chinese characters is found at: http://thevirtuosi.blogspot.com/2011/08/tweet-is-worth-at-least-140-words.html and a web frontend for the Python script that does the compression can be found at http://pages.physics.cornell.edu/~aalemi/twitter/
It's important to note that although the characters are real Chinese characters, the string that is created most likely isn't correct or meaningful Chinese when read by a Chinese person.
This extension uses the backend from the above blog post and provides a quick and dirty wrapper to encode English text as compressed Chinese characters.
Attachments:
- tomo's blog
- Login to post comments
- Comments
There are multiple modules for importing and exporting Drupal taxonomies (Drupal switches between using the term "taxonomy" and "vocabulary" like a clinical schizophrenic). Some use CSV format (http://drupal.org/project/taxonomy_csv), others XML (http://drupal.org/project/taxonomy_xml), and still others use a PHP array (http://drupal.org/project/taxonomy_export).
Some of these modules use the same paths for the export and import pages but they are different modules and aren't compatible. If you have both Taxonomy Export and Taxonomy XML installed at the same time they will conflict.
Except for CSV, the other import/export modules need you to create documents in a rather wordy XML or PHP code format, which can actually be more work than entering the terms in manually. Some people may use taxonomy import/export for only the taxonomy definition rather than terms. It's sometimes unclear what happens if you want to re-import duplicate term names later.
What worked best for me was using Taxonomy Manager which gives you an improved UI for organizing terms within a vocabulary. I wish it made editing the core fields of a taxonomy more ajax-y but what it does provide is an easy way to add multiple terms at once, a textarea for pasting in a list of terms, and a way to select where the new terms will go. So you can paste in all the top level terms, then paste in all the 2nd level children of the 1st term and select the 1st term to indicate they will all go under it. As long as you don't have too many different branches, then this can be done fairly easily.
Just an idea. There are websites that allow resuming of partially downloaded files. But even if the browser or client (curl, wget, etc.) supports resume if the server doesn't support it then you're SOL. Some websites disallow resume intentionally.
But perhaps there's a way to fake resume by telling the web server to send data that the client doesn't actually receive. So if I've already downloaded 100 MB of a file, then I would tell the server to rapidly send the first 100 MB of the file again but actually ignore it until data after the first 100 MB is sent.
TCP? TCP (of TCP/IP which runs the internet) is a "transmission control protocol" on top of IP meaning it sets up a connection between two computers which have a reason to exchange data (like a web browser on my computer and a web server out there on the internet). Part of this protocol says how one side sends a broken up piece of data and knows it was definitely received. The sender will send out pieces of data until the receiver either says to slow down, or the sender guesses that it's sending too fast for the receiver to receive. It's up to the receiver to respond saying it has received a piece of data, or all the data up to a certain point, and signal to the sender that it can either transmit data faster or slower.
You can think of it as two sentries on each end of a bridge. Each sentry allows cars to cross the bridge in one direction but to avoid the bridge from backing up (or breaking under load) the other side sends a bike messenger across to say "X number of cars have crossed; send more faster" or "it seems that car license number 1073 never made it across; send that load again".
But say we don't care about the first 100 MB of cars crossing the bridge and making it to the other side, because we already received their payload earlier. What we want to do is convince the sender to as many cars as it can as quickly as it can, causing a traffic jam which will cause cars to fall off the bridge. But we will lie and say that all the cars made it across.
The TCP equivalent would be to increase the receive window much more than usual, then periodically send ACK acknowledgement packets with fake sequence numbers, numbers which are ahead of what we've really already received. We guess what sequence number the sender has most recently sent out and tell them we have already received that packet so they can send more. We still need to know how much actual data the sender has sent so that we can tell when we need to go back to normal at 100 MB.
Could this really work? If it did, it would require more than a change to a browser or client. It would require hacking TCP itself, which is inside the operating system. Of course, with Linux of OpenBSD, it's quite possible to hack the networking code yourself to compile your own custom kernel, perhaps even as a reloadable kernel module. Then you would also need a custom client, like a modified curl/wget, that signals to the OS that a certain TCP connection should "fake download" for a number of bytes, and then the client must resume appending to a file once the OS detects that downloading has surpassed that threshold.
I can't be the only one who has thought of this, so let me know if this has actually been done before, or if not, why not?
Seesmic Web has had a problem for as long as I've used it. I was hoping they would fix it on their own but as of the last update (which broke Seesmic Web for awhile) would take care of it. The problem is that tweets or other posts just up and disappear while you're in the middle of reading them. I use Seesmic to scan a days worth of tweets because of its compactness and automatic relatively responsive infinite scroll. But you know there's a problem when all of your timeline from "2 hours ago" to "14 hours ago" is missing.
There. I fixed it.
Install Seesmic Zombie Fix for Chrome (and maybe other browsers)
The problem seems to be that Seesmic periodically culls tweets that it thinks shouldn't be shown, maybe because they're too old and there's not enough space (who knows?). This Chrome-based userscript (it should work with FireFox using greasemonkey, and also natively in Opera) watches for the tweet-snatcher to do its reaping and then saves the zombie tweets before they end up in tweet-purgatory. The "saved" tweets will then show up at the top of your timeline with a pink background on the "ago" time.
Caveats: the "ago" time will no longer be updated automatically, and other javascript-y actions on the tweets will no longer be linked up. So the expand-contract on click no longer works. I worked around this by expanding all undead tweets. But at least you will be able to read tweets from hours ago without having them "rapture" on you.
- tomo's blog
- Login to post comments
- Comments
Moving a directory out of a SVN repository: I had to do this recently. It's not a black art. It's not exactly built into subversion, but can be done using basic svn tools. In fact, instructions are in the SVN book (relevant page).
It's a simple as:
1) svnadmin dump /path/to/repos > myrepos-dumpfile
2) svndumpfilter include somedir1 somedir3 somedir5 < myrepos-dumpfile > somedirs-dumpfile
3) svnadmin create repos; svnadmin load repos < somedirs-dumpfile
That will re-create your repository with just the directories you want to keep. Then you would svndumpfilter again on the original dumpfile for any repositories you want to create out of specific directories (e.g. somedir2).
If you follow the book's instructions about ignoring UUID when restoring (--ignore-uuid) then you won't be able to use the recreated repository from places where it's currently checked out, i.e. you would have to check out again. This might make sense if you had checked out directories that are no longer in the main repository. Naturally, for any of those directoryies, you will have to check out fresh using the new repositories.
Once you've restored, you'll notice that there are "phantom revisions" for revision numbers corresponding to commits for directories no longer in the tree. You could use "—drop-empty-revs --renumber-revs" when svndumpfilter'ing but I guess this would also screw up any trees that were already checked out.
- tomo's blog
- Login to post comments
- Comments
I have turned the Correct Horse Battery Staple post's Foreign Language Random Password/Passphrase Generator into a Google Chrome extension.
Here is what it looks like:
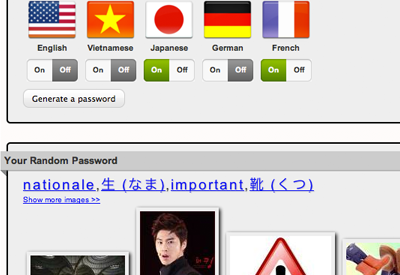
And in the Chrome web store:

Go install it and easily generate a secure and memorable passphrase anytime you need it!
Attachments:
- tomo's blog
- Login to post comments
- Comments
Inspired by XKCD, this is a password generator for those of you who know English and Vietnamese or another language. Once a random set of words in your languages has been generated, images for those words will be shown to help you visually remember your new password. If the random password seems too hard to remember, you can always spin the wheel a second time!
Each time you click, 4 random words from the selected languages will be loaded. I chose the number 4 so as to not overload Google Image search, so you may want to run it twice to get 5 or more words for added security. I find that the images help to visually remember the password.
If you still want a password like "!Agt:m%p>" then it's also an option below.
Your Random Password
Click that button up there!
The other day there was an XKCD strip about password security. The idea is that we've been trained over the years to use passwords like 'Tr0ub4dor&3' because they mix upper and lower case, use numbers, and special characters. But a password like that is based on a common English word using a common substitution pattern (l33tsp34k) of letters for numbers and is much easier for a hacker to guess than four random words like 'correct horse battery staple', which is longer but much easier to remember.
A good password should be random. Humans aren't random and 'Tr0ub4dor' looks random enough but it isn't. Even translating the word into a foreign language is by itself weak. Generally, if you come up with the password yourself then it's not anything close to random.
Plenty of software exists to come up with passwords made up of random characters. The problem is that these passwords weren't meant to be memorized. Writing your password down somewhere sort of defeats the purpose.
So four random English words makes a pretty good password, but is still hard to remember if they are obscure and unfamiliar words. Out of the over one hundred thousand words in an English dictionary a few thousand are commonly used.
So a few thousand English words are generally useful. But those of us who are bilingual can basically double the size of the vocabulary used! This foreign language random password generator seeks to take advantage of that numerical weapon, and with a large number of possible languages (and even more language combinations), even if a hacker got an encrypted password file it would be as hard to crack as a random 9-character totally impossible to remember string.
You can increase the security of your password further by using a "salt" random string (non-dictionary word) that you remember and always use with your passwords, and by adding punctuation in one of the words.
UPDATE: There is now a Chrome extension that makes creating passwords on the fly really fast and easy! Check out the Correct Horse Battery Staple Google Chrome Extension
- tomo's blog
- Login to post comments
- Comments
The internet speed in Vietnam is back to dialup level. There are rumors of another cable cut as well as maintenance that will last more than another week. This after weeks of "undersea cable maintenance" after which we had awesome download speeds for awhile. This means a lot of large transfers from sites outside of Vietnam are unbearably slow. In the meantime, go buy your favorite movies or TV shows on DVD for 10,000 VND, it'll be quicker.
There is a time of day when speeds are much better. It's in the wee hours of the morning, when most of the population has stopped downloading porn for the day.
If you're slightly resourceful you can take advantage of that window of high speed internet by downloading to a server outside Vietnam during the daytime and then downloading from there to your home PC at nighttime.
Attachments:
I needed to test out ssl on my Macbook as a web server with XAMPP. It took more effort than it should have because I was using virtual hosts as well.
Read the rest of this article...
© 2010-2014 Saigonist.
Recent comments
1 year 11 weeks ago
2 years 3 days ago
2 years 1 week ago
2 years 3 weeks ago
2 years 19 weeks ago
2 years 19 weeks ago
2 years 19 weeks ago
2 years 19 weeks ago
2 years 19 weeks ago
2 years 19 weeks ago